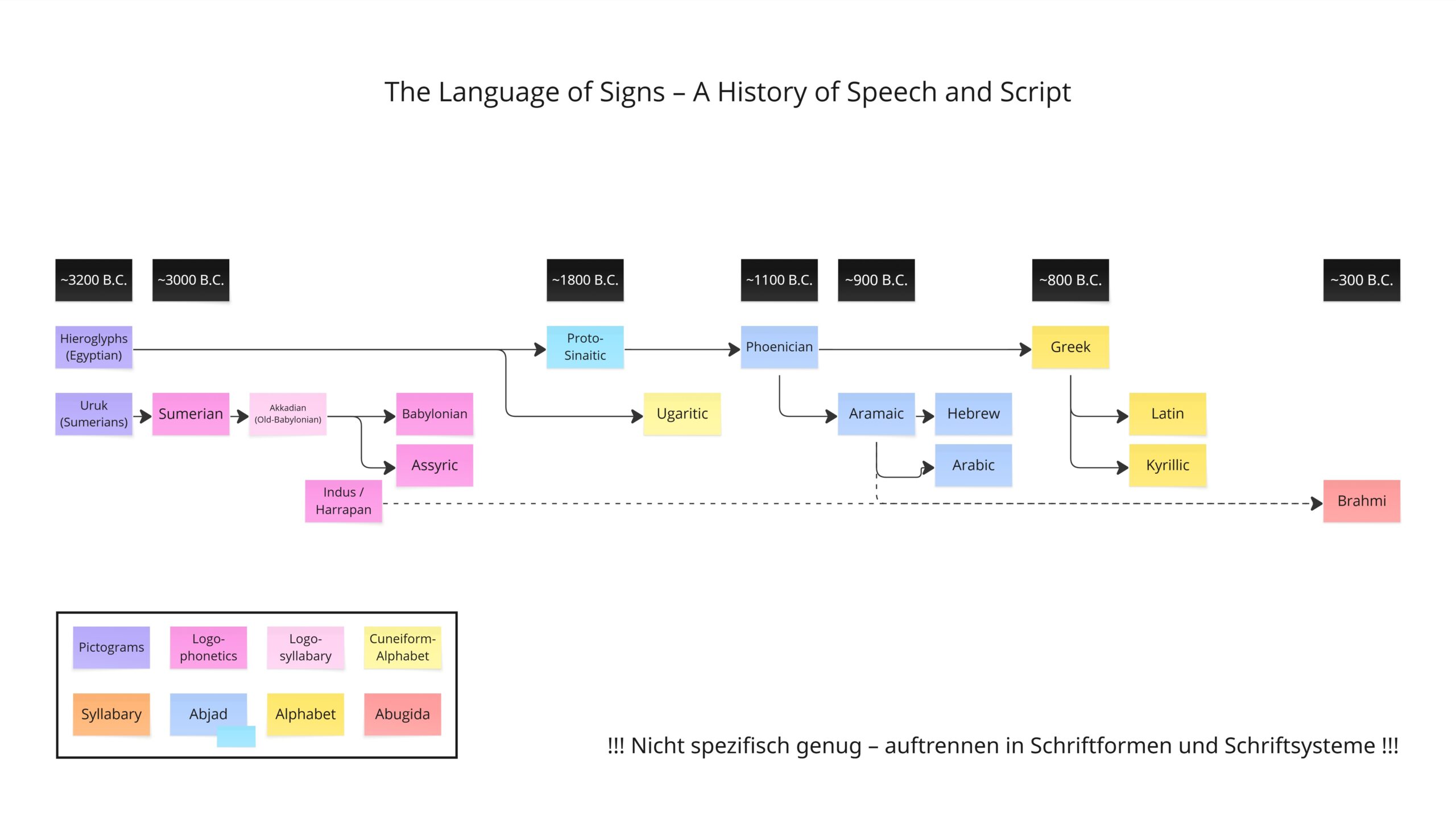
Schriftsysteme
Japanisch nutzt eine Silbenschrift, Deutsch nutzt eine Buchstabenschrift. Aus dieser Unterscheidung ergibt sich die naheliegende Frage: Gibt es noch weitere Typen? Ja – dazwischen passt noch die Abugida, die es in zwei Varianten gibt: typisch und atypisch, sowie Piktogramme, Bilder, Keilformen und der Abjad (Konsonantenschrift).
Ich beschränke mich ab hier auf Buchstaben-/Silbenschriften und der Abugida. Andere Schriftsysteme habe ich nicht berücksichtigt – reine Geschmackssache und zu viele Köche verderben bekanntlich die Suppe.
Um die relevanten Begriffe korrekt einzuordnen – und keine Äpfel mit Birnen zu vergleichen – müssen wir zunächst noch mal über die Silbe sprechen. Eine Silbe besteht aus mindestens zwei Lauten. Für die folgenden Vergleiche beschränke ich mich auch auf exakt zwei Laute pro Silbe. Komplizierter macht den Vergleich nämlich nicht besser.
Die einfachste Form ist eine Konsonanten-Vokal Kombination – zum Beispiel Ga oder Ne. Ein Buchstabe repräsentiert hingegen meist nur einen konkreten Laut. Wir müssten also sagen, eine Silbe entspricht einem Buchstabenpaar aus zwei Buchstaben um, mathematisch formuliert, den kleinsten gemeinsamen Nenner zu definieren.
Was sind die relevanten Unterschiede? Eine kurze Übersicht mit darauffolgenden Bildbeispielen:
- Buchstabenschrift:
- Kleinste Einheit: Buchstabe
- Beispiel: A, B, C, …
- Sprachen:
- Deutsch
- Englisch
- Latein
- Abugida:
- Kleinste Einheit: Basiskonsonant mit inhärentem Vokal
- Beispiel: Ka, Ke, Ki, Ko
- Typisch: Grundzeichen für z.B. K plus Zusatz/Modifikator
- Sprachen:
- Devanagari (Sanskrit)
- Äthiopisch
- Faredisch (meine erfundene, hier vorgestellte Sprache)
- Sprachen:
- Atypisch: Grundzeichen ohne Zusatz. Wird stattdessen um je 90° gedreht, inhaltich aber nicht verändert.
- Sprachen:
- Inuktitut / Inuit-Sprachen (Nordamerikanische Ureinwohner)
- Sprachen:
- Typisch: Grundzeichen für z.B. K plus Zusatz/Modifikator
- Silbenschrift:
- Kleinste Einheit: Silbe (Bild/Symbol/Zeichen)
- Beispiel: Ka, Ke, Ki, Ko
- Die Zeichen stehen in keinem Zusammenhang zueinander
- Sprachen:
- Japanisches Hiragana/Katakana
- Cherokee
Darüber hinaus gibt es noch Schriftsysteme des Typs Abjad (etwa im Semitischen, wie Arabisch oder Hebräisch) die ausschließlich Konsonanten notiert, sowie Logogrammschriften, wie sie im Chinesischen bis heute verwendet werden – und wie sie in vielen deutlich älteren Schriftsystemen vorkommen, die teils über 2.000 bis 3.000 Jahre alt sind. Unter anderem Sumerisch, ein Vorläufer des Babylonischen. Dies nur zur Vervollständigung.
War das einfach genug als Einstieg? Ich hoffe sehr, doch gönnen wir uns dennoch eine kurze Verschnaufpause und schauen uns diese Unterschiede anhand Bildern von einzelnen Symbolen an.
Darstellung der Schriftsysteme
Fangen wir mit den uns bekannten Buchstaben an. Wie soeben ausgeführt müssen wir unsere Buchstaben als Buchstabenpaare denken, um einen Vergleich herstellen zu können.
Daher benenne ich hier willkürliche Konsonanten-Vokal (CV) Paare – zum Beispiel Ya, Ye, Yi, Yo und nicht nur einzelne Buchstaben.
Diese können wir dann folgenden Symbolen gegenüberstellen.

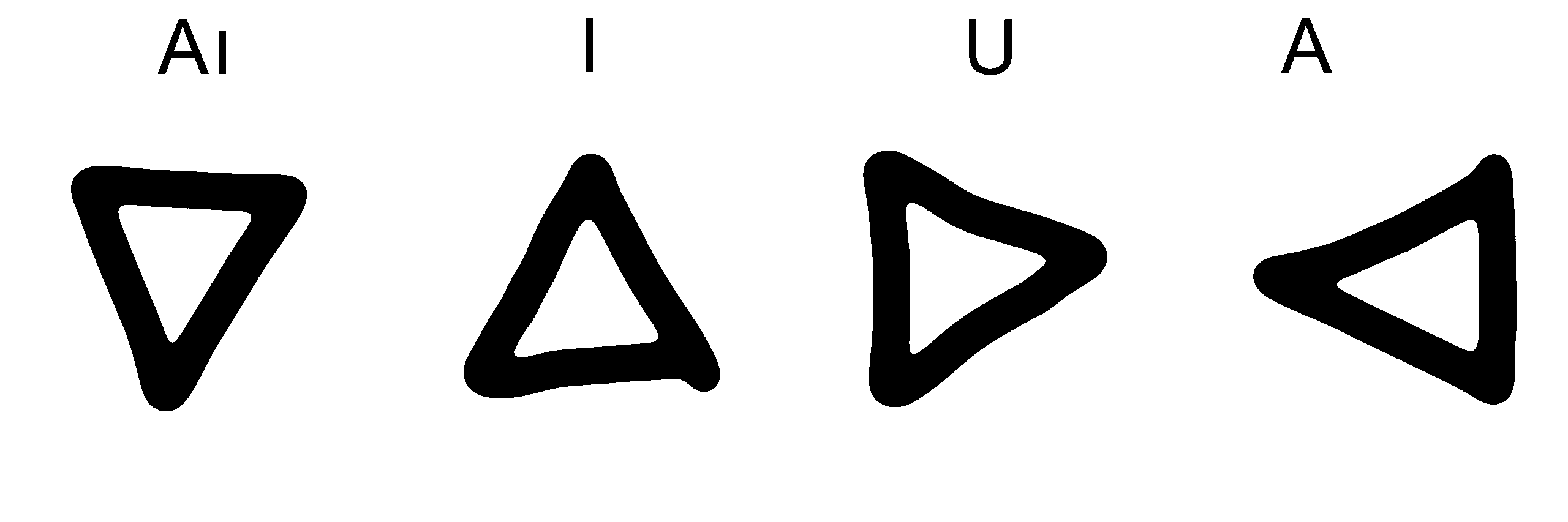
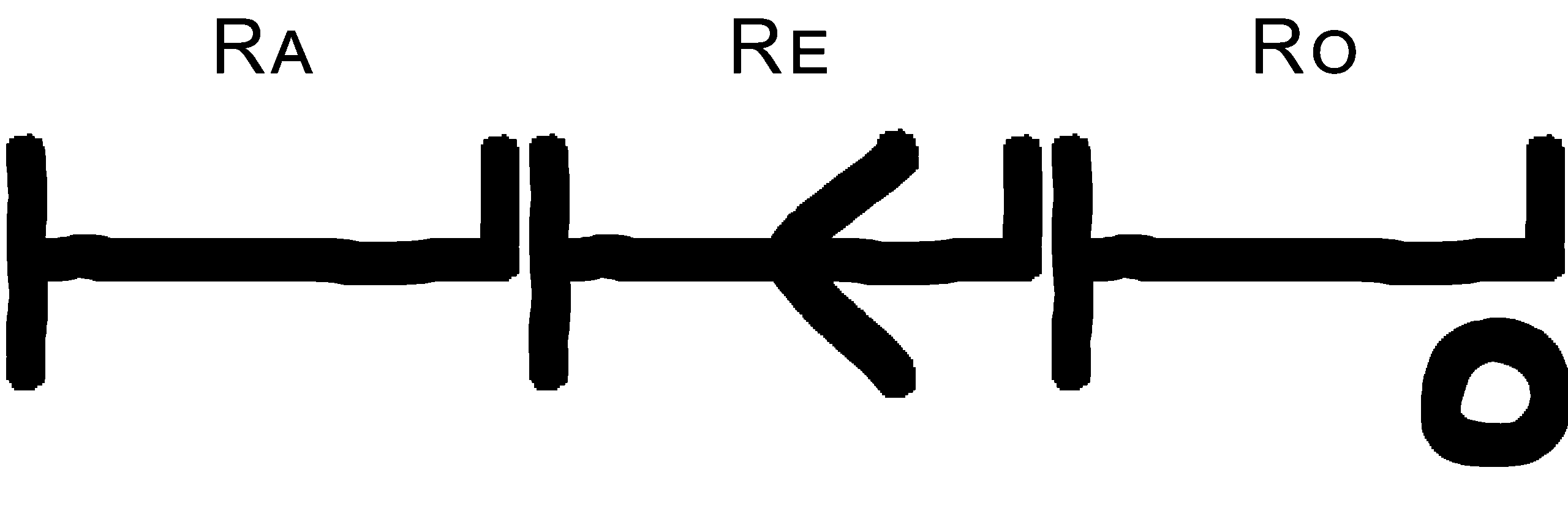
Wie wir sehen, können wir jedes Bildsymbol auch durch Buchstaben darstellen.
Eine erfundene Sprache
Die erste Version meiner Sprache, die später den Namen Faredisch bekommen sollte, basierte auf all dem, was ich bis hierhin erklärt habe … nicht!
Wie ich in der Einleitung bereits erwähnt habe, basierte meine erste Idee auf dem Layout eines alten Tasten-Telefons. Aus Bequemlichkeit wollte ich einfach mit möglichst wenig Symbolen auskommen, um den Aufwand zum Erlernen später nicht ausufern zu lassen.
Ovu – Faredisch (Version 1)
Ohne zu Wissen was ich da eigentlich tat, legte ich einfach los und definierte meine erste Regel. Das lateinische Alphabet wird, wie auf der Handy Tastatur, in 3er Blöcke geteilt. Jeder Block erhält ein eigenes Symbol. Dabei wird der jeweilige Buchstabe im Block durch einen Zusatz angegeben. Wie konnte so etwas aussehen?
In Textform:
- 1. Block: ABC
- 2. Block: DEF
- 3. Block: GHI
- … und so weiter …
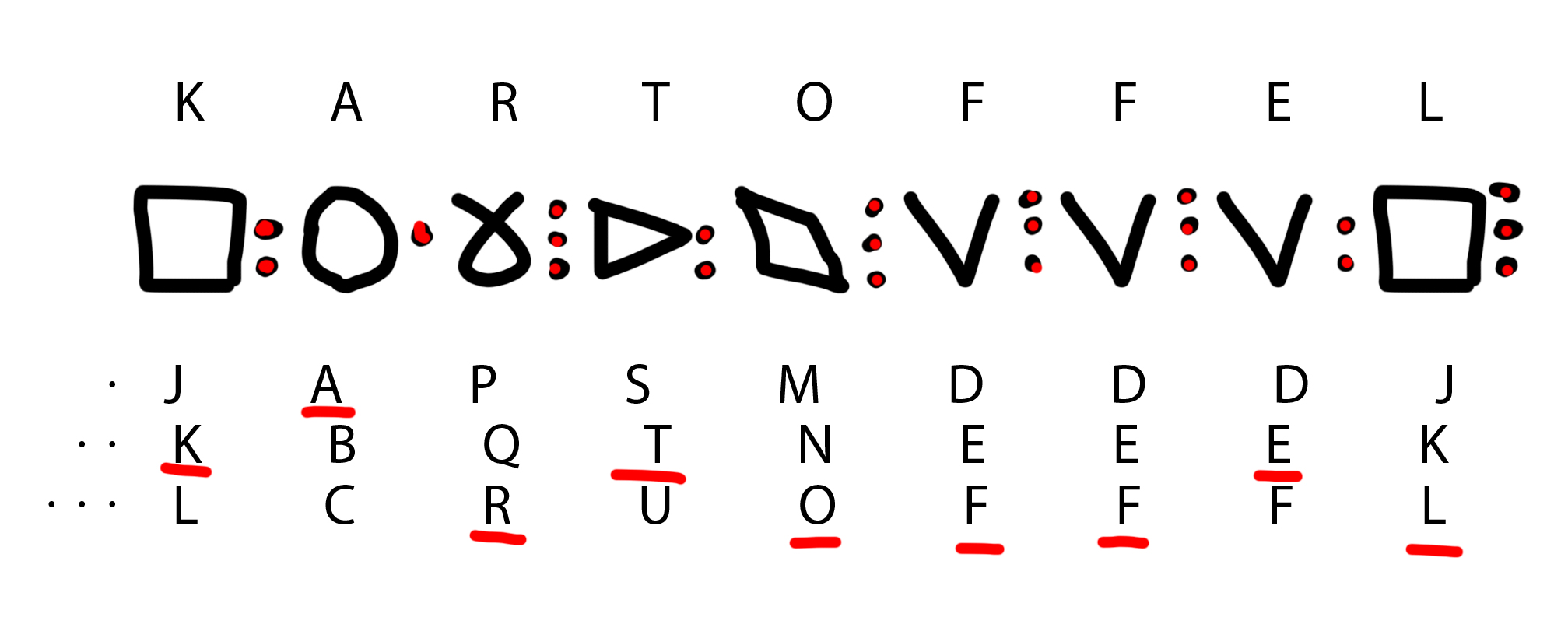
Um es einfach zu halten legen wir nun fest, dass jeder Block aufsteigend durchnummeriert wird. ABC würde also über eine 1 dargestellt. Da wir so aber nicht wissen welche 1 wir konkret meinen, wird die Position im Block (1-3) über je einen Punkt hinter dem Grundzeichen dargestellt. Für A also 1*, für B dann 1** und für C entsprechend 1***. Für den zweiten Block mit den Buchstaben DEF entsprechend 2*, 2** und 2***.
In meinem Notizblock sah das dann so aus:
Für die Grundzeichen hatte ich mir überlegt, mit einem Kreis zu beginnen und pro Block eine Kante hinzuzufügen. Das hätte mit einem Achteck für XYZ geendet. Die Sprache sollte zu diesem Zeitpunkt Ovu heißen – entsprechend der Formen O (keine Ecke), V (eine Ecke) und U (zwei Ecken). Damit hätte ich bereits arbeiten können, aber die Ästhetik hat mir überhaupt nicht gefallen. Diesen Aspekt hatte ich aber auch nicht berücksichtigt – viel zu monoton und langweilig.
Durch gezielten Bruch in der Formgebung und Einschub von untypischen Symbolen im Kontext bereits bestehender Symbole wurde das Schriftbild besser, es reichte mir dennoch nicht. Ein Versuch diese Langeweile aufzubrechen:
Kurz darauf enstand die Idee für das, was nun Faredisch genannt wird.
Faredisch als Alphabetschrift (Version 2)
Die simplen Formen der ersten Version waren zwar leicht zu erlernen, aneinandergereiht in Worten sah das Schriftbild allerdings weiterhin grässlich monoton aus. Der zweite Versuch baut daher auf 6 Grundzeichen mit Balken drüber oder drunter als Modifikatoren auf. Mit dieser Erweiterung der ersten Version habe ich zwar eine deutliche visuelle Verbesserung erreicht, doch irgendetwas stimmte noch immer nicht.

Später wusste ich – die Symbole funktionieren gut als Druckbuchstaben, lassen aber kaum Kreativität für eine fließende Schreibschrift zu. Mit dieser Version habe ich darüber hinaus nichts weiter, als eine stinknormale Alphabetschrift erfunden – eben nur mit eigenen Symbolen. Wir könnten Deutsch mit diesen Symbolen schreiben, es könnte ein deutscher Sprecher nur nicht lesen. Doch eine Erkenntnis aus dieser Version ist, dass die Symbole sich nicht zu sehr ähneln dürfen. Sonst wirkt das Schriftbild sehr monoton im Fließtext.
Faredisch als atypische Abugida (Version 3)
Bis zur dritten Version gab es nur Laute und Symbole. Die ersten beiden Ansätze hätte man durchaus fortführen können, doch die benannten Schwächen wären geblieben.
Mit dieser Version änderte ich zwei elementare Parameter der Schrift.
- Ein Symbol repräsentiert nicht länger einen Buchstaben/Laut, sondern ein Lautpaar – eine Silbe.
- Die Grundzeichen sollen durch Rotation zu konkreten Silben werden.

Zu diesem Zeitpunkt dachte ich, ich wäre ein pfiffiges Kerlchen … aber wie ich kurze Zeit später feststellte, waren die amerikanischen Ureinwohner schon vor Jahrhunderten mindestens genau so pfiffig… Ich hatte eine atypische Abugida entwickelt.
Davon abgesehen, dass dieses System bereits erfunden war gefiel mir diese Version schon richtig gut. Die Fülle an unterschiedlichen Symbolen lieferte ein abwechslungsreiches Schriftbild. Auch hatte ich das erste faredische Wort definiert – Ahimotu, was für Sprache bzw. Verständnis steht und sich aus Hahi (Zunge) und Motu (gemeiner Mensch, ferner Gesellschaft) bildet.
Ich hatte mit dieser Version tatsächlich die Schriftentwicklung gedanklich bereits abgeschlossen.
Doch mit den ersten Schriften – eher kurzen Texten – stellte sich schnell heraus, dass die Schreibgeschwindigkeit stark eingeschränkt war. Einige Symbole sind durch das Drehen für Finger und Hangelenk ungewohnt, wodurch das Tempo stark litt.
Ich entschied mich dazu gänzlich von vorne zu beginnen. Der kurzzeitige Frust über die Erkenntnis nichts Neues erschaffen zu haben führte letztendlich zu dem Impuls den nächsten Versuch erst zu wagen, wenn gewisse Themenfelder der Linguistik verstanden waren. Mein Interesse am Thema war vollständig geweckt.
Faredisch als typische Abugida (Version 4)
Das Faredische in seiner aktuellen Version ist eine typische Abugida geworden. Das bedeutet, wie wir zu Beginn des Artikels festgestellt haben, eine Silbe ist die kleinste Einheit und bildet sich aus einem Grundzeichen und einem Zusatz, als Modifikator bezeichnet.
Langsam verstand ich, dass ich bis hier hin hauptsächlich an einem Schriftsystem gearbeitet habe und weniger an einer Sprache. Mit fortschreitendem Lernerfolg verstand ich auch, welche Einzelteile eine Sprache eigentlich ausmacht. Bisher habe ich mich auf die verschiedenen Schriftsysteme bezogen.
Bevor wir nun zur Sprache kommen, werfen wir erneut einen Blick in die bereits vorgestellte Phonetik und Phonologie. Ein schneller Rückblick:
Es galt also, ein Liste erlaubter Laute zu definieren und dazugehörige Symbole zu entwerfen.
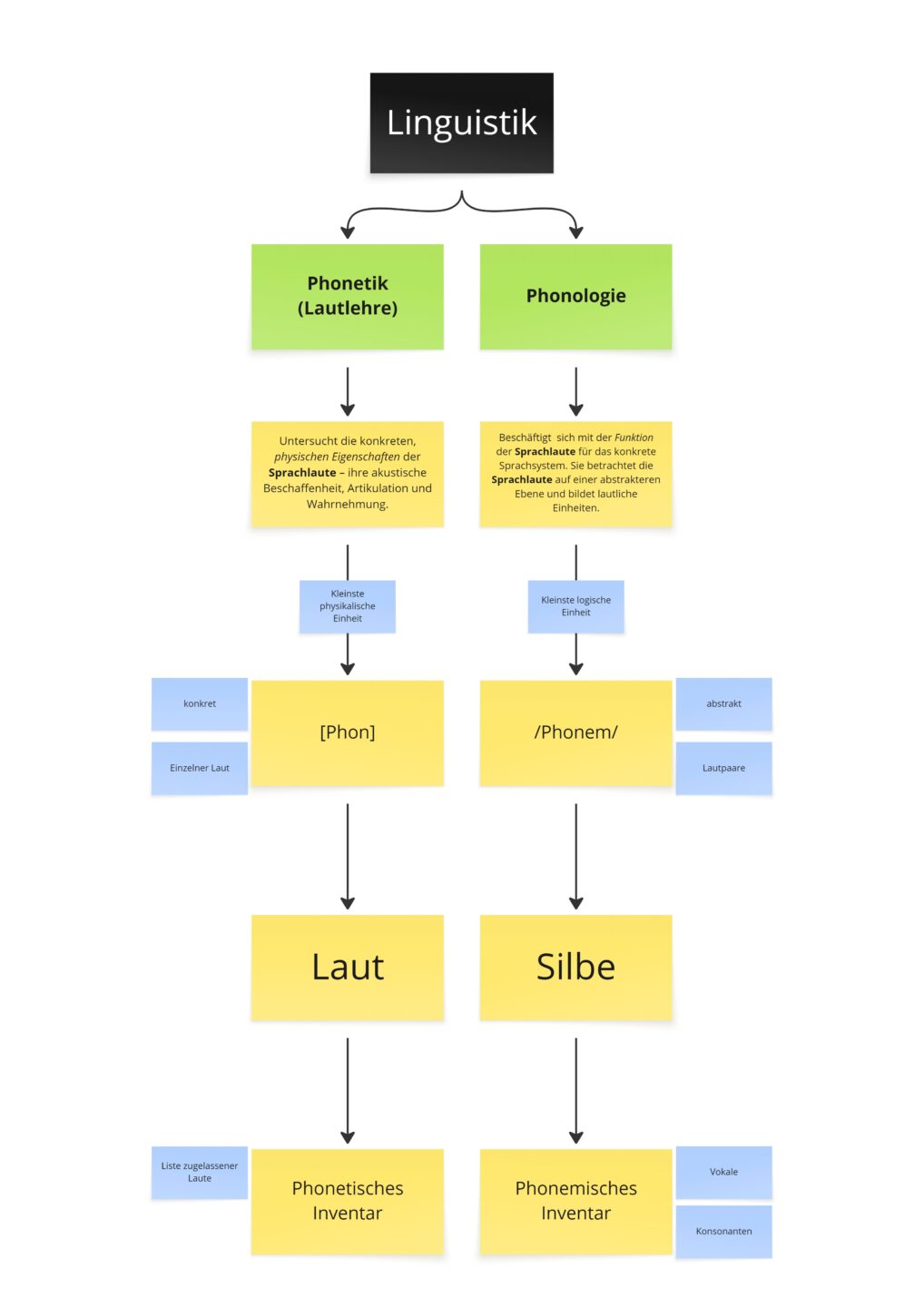
Phonetik
Da sich Phonetik und Phonologie als Begriffe zu sehr ähneln, habe ich mir eine Eselsbrücke gebaut. Phonetik ist wie Genetik und gehört zur Biologie. Das mag falsch sein, aber durch die gleiche Endung und der bewussten Lüge kann ich mir das leichter merken. Phonetik schaut ganz konkret und physikalisch, teilweise recht mechanisch, auf den Bereich Mund, Zunge und Hals und was wir damit anstellen können.
Wenn wir laut ausatmen kommt bei den meisten ein aaaaaa, vielleicht ein hhhhaaaa heraus. Wenn wir den Mund schließen und anfangen zu summen kommt ein mmmmm heraus. Nur darum gehts, mehr ist es nicht.
Eine Übersicht kann hier eingesehen werden: IPA Tabelle, Rev. 2020
Für Faredisch habe ich mich auf 21 Buchstaben beschränkt und um Verwechslungen und Missverständnisse auszuschließen, die Unicode Repräsentation herausgesucht. Dies schien mir eindeutiger als IPA Tabellen in verschiedenen Versionen berücksichtigen zu müssen.
In diesem Schritt habe ich zu ähnlich klingende Laute reduziert. Deswegen existiert beispielsweise das B im Faredischen nicht. B ähnelt in der Aussprache zu sehr dem D. Ein Q kann stumpf über Ku notiert werden. Die deutsche Abweichung zum Internationalen im Bezug auf C, S, ß, sch und weitere Zischlaute… gleiches Spiel mit F, V und W. Solche Aspekte habe ich berücksichtigen wollen.
Die vollständige Liste erlaubter Laute lautet: a, s, d, e, f, g, h, i, k, l, m, n, o, p, r, z, t, v, j, sch, w.
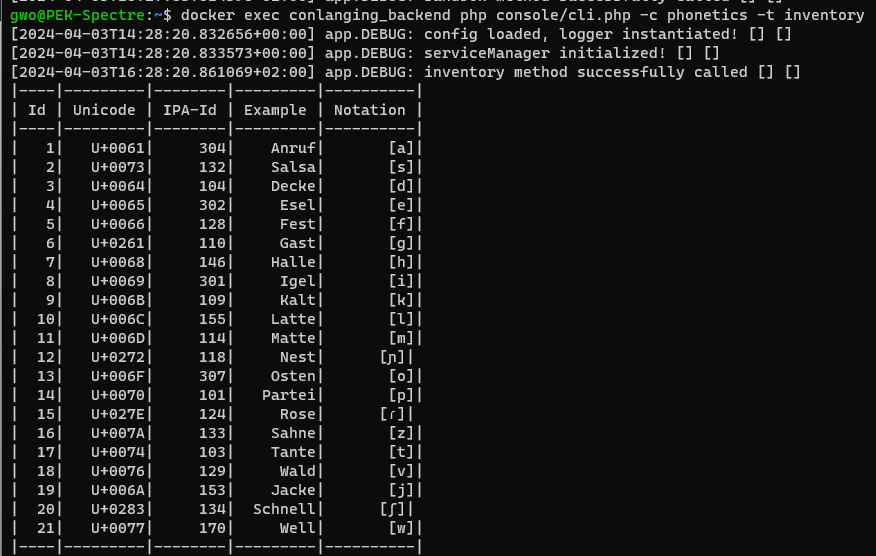
Phonologie
In der Phonologie werden die Laute, die in der Phonetik festgelegt werden, zu logischen Einheiten weiterverarbeitet. In einer Alphabetschrift wie Latein entspricht zum Beispiel der Laut G direkt dem Buchstaben G. Bei einer Abugida oder Silbenschrift benötigen wir mindestens zwei Laute, um die kleinste Einheit bilden zu können.
Da ich bereits in der Phonetik meine Wünsche umsetzen konnte, blieb für die Phonologie nicht mehr viel übrig. Die Entscheidung für einen Mehrfachlaut (Silbe) als Grundeinheit war schon lange getroffen. Nach der Reduktion mochte ich nur zwei Phoneme hinzufügen.
- Das Sch sollte ein eigenständiger Laut werden.
- Das X sollte als Konsonanten-Cluster /ks/, soweit verstanden auch konsonantischer Digraph genannt, realisiert werden.
- Das harte deutsche W (V im Englischen) sollte das deutsche V erübrigen und mit der englischen Entsprechung gleichgestellt werden.
- Dadurch entstand Raum für ein weiches W (Whiskey oder Well auf Englisch – das W summt hier nicht – die oberen Vorderzähne berühren die untere Lippe nicht).
Damit hatte ich das phonemische Inventar vervollständigt und das sah wie folgt aus:
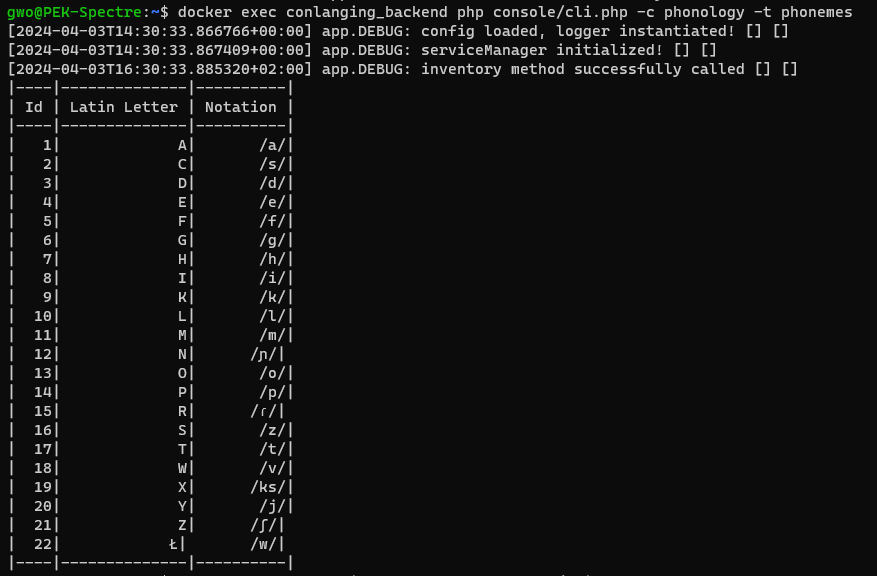
Damit war die Phonologie aber noch nicht ganz abgeschlossen. Die ausgewählten Phoneme mussten nun eine Funktion erhalten. Um es nicht unnötig zu verkomplizieren: A, E, I und O habe ich als Vokale festgelegt. Alle anderen Phoneme sind Konsonanten.
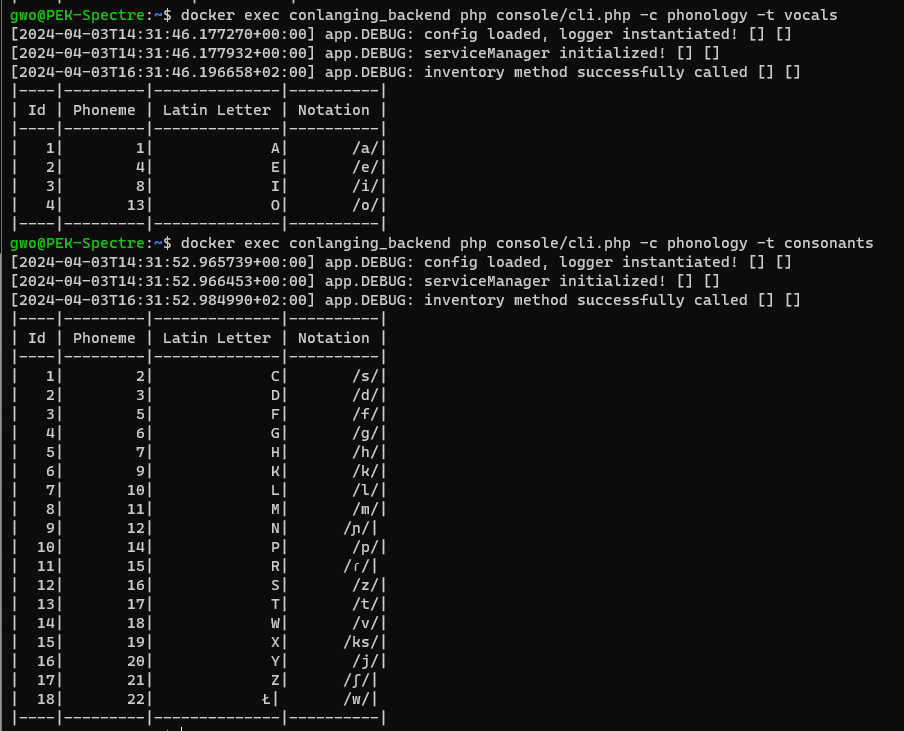
Für die vierte Version des Faredischen bedeutete dies, dass sich 4x 18 Silben bilden lassen. Jeder Vokal kann mit jedem Konsonanten zu einer Silbe gepaart werden. Wir erinnern uns: Typische Abugida, Grundzeichen plus Modifikator. Dabei bilden die Konsonanten das Grundzeichen – in meinen Worten – Stammform. Die konkrete Silbe wird dann über den Modifikator – in meinen Worten – Vokalakzent hinzugefügt. Darüber hinaus existiert zu jedem Konsonant-Vokal-Paar (CV, Anlaut) auch die umgedrehte Form (VC, Auslaut) und wird über einen Auslaut-Akzent notiert.
Da ich alleinstehende Vokale erlauben wollte, die über ein CV Paar mit stummen H realisiert werden, ergeben sich daraus insgesamt 76 faredische Silben: a, e, i, o, ca, ce, ci, co, da, de, di, do, fa, fe, fi, fo, ga, ge, gi, go, ha, he, hi, ho, ka, ke, ki, ko, la, le, li, lo, ma, me, mi, mo, na, ne, ni, no, pa, pe, pi, po, ra, re, ri, ro, za, ze, zi, zo, ta, te, ti, to, va, ve, vi, vo, xa, xe, xi, xo, ya, ye, yi, yo, za, ze, zi, zo, Ła, Łe, Łi, Ło.
Die faredische Silbe
Das faredische Schriftsystem nutzt die Silbe als kleinste Einheit. Silben können über verschiedenste Strukturmodelle aufgebaut werden. Zum Glück müssen diese nicht alle beleuchtet oder gar verstanden werden, um den Zweck mitnehmen zu können. Mit Blick darauf, eine möglichst einfache und reduzierte Sprache zu entwickeln, suchte ich nach dem für mich einfachsten Strukturmodell.
Und das waren: Einfache Konsonanten-Vokal-Paare!
Jede Silbe besteht aus einem Konsonanten und einem Vokal. Dabei sind nur CV-Paare (Konsonant-Vokal-Paare oder Anlaute) und VC-Paare (Vokal-Konsonant-Paare oder Auslaute) erlaubt. Später wird diese Regel aufgeweicht, doch das betrifft das Sprachsystem. An dieser Stelle beschränken wir uns weiterhin auf das Schriftsystem.
Was das konkret bedeutet, lässt sich an einer handvoll willkürlicher Worte darstellen.
Erlaubt sind Wörter wie: Yamo, Talona, Kalera, Alma, Fisanaru, Amer. Die Anzahl der Silben variiert, doch jede Silbe basiert entweder auf einem CV- oder VC-Paar.
Nicht erlaubt sind Wörter wie: Fast (CVCC), Klar (CCVC), Wetter (CVCCVC), Langsam (CVCCCVC). Sie brechen die CV/VC Silbenstrukturregel.
Und damit bin ich auch mittendrin in der Grammatik gelandet – über die Phonologie als erster Baustein.
Bevor es nun aber mit der Morphologie und damit dem Sprachsystem weitergehen sollte, musste ich die Stammformen und Vokalakzente, sowie Auslaut Notation festlegen – oder mit einfachen Worten: Jede Silbe benötigte ein Symbol.
Grundformen und Akzente
Eine Mischung aus Hieroglyphen, keltischen und mesopotamischen Zeichen führte zu dem finalen Schriftbild. Diese Zeichen funktionierten endlich sowohl in Druckschrift, als auch in handschriftlicher Form.

Während der Entwicklung dieser Zeichen habe ich darauf geachtet wiederkehrend Basiselemente zu verwenden, dazu zählen die Querbalken (D, R, Z, N, C, L, T, H), oder die Dreiecke als Darstellung von Kreisen (K, S, P, X, T). Dadurch wirkt das Schriftbild divers, ist durch die Wiederholung aber leichter zu erlernen.
Um später keine Zeit mit dem handschriftlichen Schreiben von Wort- und Textproben zu verlieren, schließt die Schriftsystementwicklung für mich als Programmierer mit einem Font für die faredische Abugida ab.
Nicht nur das Suchen & Ersetzen bei Anpassungen an Wörtern wird dadurch erheblich erleichtert.
Finale Übersetzungstabelle
Sind alle Tassen im Schrank?
Ich hatte alle Bausteine beisammen, um mit der Entwicklung von Wörtern und dazugehöriger Grammatik beginnen zu können. Eine vollständige Liste erlaubter Laute, die dazugehörigen Symbole und ein grundlegendes Regelwerk (Silbenstruktur).
Um nicht willkürlich Wörter aus dem Hut zaubern zu müssen, bemühte ich mich um ein System, an dem ich mich orientieren könnte. Leider habe ich bisher nichts gefunden, was meine Anforderungen erfüllen konnte. Daher habe ich ein eigenes visuelles System entwickelt, welches ein Mix aus Vokalgeometrie, Farblehre, Harmonielehre (Musik) und phonetischer Artikulationslogik darstellt.
Ein Begriff schien mir passend: Das faredische Harmoniesiegel